本文主要是想配合这篇关于人口合成的文章,谈谈怎么准备普查数据集和微观数据集。美国的数据开放性较高,所以都有官方数据可用,想研究哪里就下载哪里的数据即可。不过,可能也是因为开放性太高,数据量非常大,信息很繁杂,数据处理也不是那么简单,以至于除了傻瓜式的下载之外,还有官方的API和第三方开发的编程模块辅助。这里就重点说一下synthpop这个Python模块在下载和处理这些数据时的用法,毕竟这个包的帮助文件真是令人发指的匮乏,不折腾一波根本就是云里雾里。另外,国内的数据开放性还有很大差距,希望以后能迎头赶上。
ACS数据
PS:准确地说,本节及后面说的ACS数据其实是ACS summary files数据,但是习惯问题,就直接称为ACS数据了。
概况
说到普查数据,美国最全面的普查是10年普查(Decennial Census),但这个数据有两个问题:(1)十年一轮,所以许多时候会有点滞后;(2)由于要调查很有的人,为了节省资源,每个人只问题最根本的10个问题,信息维度比较单薄。
ACS则是另一种相对小样本的普查,它是美国社区调查(American Commuty Survey)的缩写。ACS的抽样率为1%,也就是每次调查的样本大概是300多万,样本是从地址库中随机抽取的。虽然是抽样调查,但是ACS会基于十年普查进行数据处理,所报告的结果仍然是普查性质的。比如说,去查ACS中的美国总人口,不是300多万,而是3.2个亿。与十年普查相比,ACS虽然样本覆盖没那么全,但是有2个优势:(1)每年都发布最新数据,所以时效性好得多;(2)每个样本会问72个问题,信息维度丰富得多。由于这2个优势,所以之前的美国研究中,都是使用ACS数据作为人工合成的普查数据。单论实践应用价值而言,我感觉ACS有点类似于国内的统计年鉴、统计公报。
ACS发布的是数据按照空间统计单元汇总之后的结果,而非微观个体数据。例如,ACS不会告诉你一个地方的每个人具体是男是女,多大年纪,只会告诉你这里的男人有多少,女人有多少,不同年龄段的人各有多少,这种其实就是性别、年龄的边缘分布。另外,由于ACS带有抽样性质,所以结果只是对总体的估计值,即estimates,且估计结果都有误差,即margins of error。ACS会同时报告estimates和margins of error,只不过实际工作中主要用的是前者。
空间统计单元
相比于国内统计年鉴中省——市——县的空间单元,ACS的空间单元要丰富的多。下面两张图截取自Census Bureau的某次演讲。左图反映了层级化的空间统计单元,其中的主线是: 国家(Nation)→ 州(State)→ 县(County)→ Tract → Block Group → Block。从Tract以后我也不知道怎么翻译比较好了,只知道Tract的范围大概是一个Neigborhood,最好在4000人左右(1000~8000人),Block Group是它的下级单位,每个Block Group又包含了几个Block。这里没有把Block直译成街区,是因为它是指Census Block,与真正的街区Street Block虽然很像,但还是有些差别。不纠结的话就把最下层的Block理解为由街道围成的街区吧。我们都知道美国的州对应中国的省,美国的县与中国的地级市相近,至于从Tract到Block,大概可以对应国内的街道、普查区、普查小区,当然这两个系统在规模、尺度上肯定还是很多差异,只是想强调这是一个从上到下的层次结构。除了这样的层级以外,每个层次还会分出一些空间单元系统,但这些不是重点,就不多说了。

下面这张图以加州的一个Block为例,展示了州在国家中的位置,县在州的位置,Tract在县的位置,Block Group在Tract中的位置,Block在Block Group中的位置。

数据获取方式
国内的统计年鉴一般以固定形式的表格呈现给大家,使用者没啥自由,给你啥就只能用啥。ACS则更像是一个数据库,你需要设定一系列的搜索和过滤条件,才能拿到想要的数据。那么如何搜索和获得数据呢?大概有4种方式。
- 通过官方搜索页面“Explore Census Data”获取:这是最直观的方式,以前Census有一个FactFinder,最近停止服务了,这个“Explore Census Data”大概就是它的替代品。这种方式没啥难度,唯一的劣势大概就是当处理批量数据的时候会比较慢吧。
- 自己下载源数据,然后搜索需要的列,取出数据:这可能是最接近国内找统计年鉴时的方式,所以也是我当年初次接触ACS时使用的方式。最大的好处可能就是一下搞来很多数据,有一种一切尽在我手的感觉。但是,如果不熟悉ACS的数据结构的话,处理这些表格可真是噩梦,能把人绕得云里雾里的,所以我是相当不推荐的。当然了,如果已经非常熟悉这些表格的结构和处理流程的话,当我没说。
- 通过官方提供的API获得:具体而言就是把你的搜索条件按格式转译一下,形成一个URL,放到浏览器或代码中请求数据。这种方式的好处是比较灵活,如果使用代码去请求URL的话,对付批量数据也是得心应手。
- 通过第三方库获得:Python中处理Census数据的第三方模块,其基本逻辑是对上述API做一个包装,用户可以以更简单的方式设定搜索条件,然后模块会帮我们一站式地完成以下步骤:生成URL、发送请求、返回数据。由于这种方法可以看做是第3种方式的高级版,所以我一般不用第3种,就只用这第4种。
下面就分别演示一下第1、2、4这三种方法,用它们获取相同的数据。要获取的数据是麻州Suffolk县的教育数据。
Explore Census Data
首先打开https://data.census.gov/cedsci/网址,进入Explore Census Data页面。
在搜索框中输入搜索主题词,这个框相当灵活。比如,我输入了3个主题词:Education Suffolk MA,它们之前用空格隔开,结果如下(此时的URL变成了这个)。系统自动把“Education”作为Topic,把““Suffolk County, Massachusetts”作为Geography。下面的结果中,最上面显眼的位置结出了一个小结论:该县的学士及以上学位比例的估计值为48.2%,误差为1.1%。如果我们是做分析的,看到这个结论已经觉得挺有意思了。但是我们现在是要数据,所以往下看,系统报告了一堆的表,每个表都有主题,数据源(截图中都是ACS),可用年份,以及表名。

在下面找到“Load More”,点击加载更多的表,找表名为“B15001″、主题为“SEX BY AGE BY EDUCATIONAL ATTAINMENT FOR THE POPULATION 18 YEARS AND OVER”的表,即18岁以上人口按性别*年龄的教育水平分布。这种以B开头的表名代表了基础表(Base),是最常用的表。点击加载这个表,长下面这个样子(此时的URL变成这个)。从第一行的表头可以看到,这个表是整个县的汇总表,每个项目包括估计值Estimate和误差值Magin of Error。下面的每一行对应一个项目,是按照性别和年龄统计的不同教育程度的人口数量。
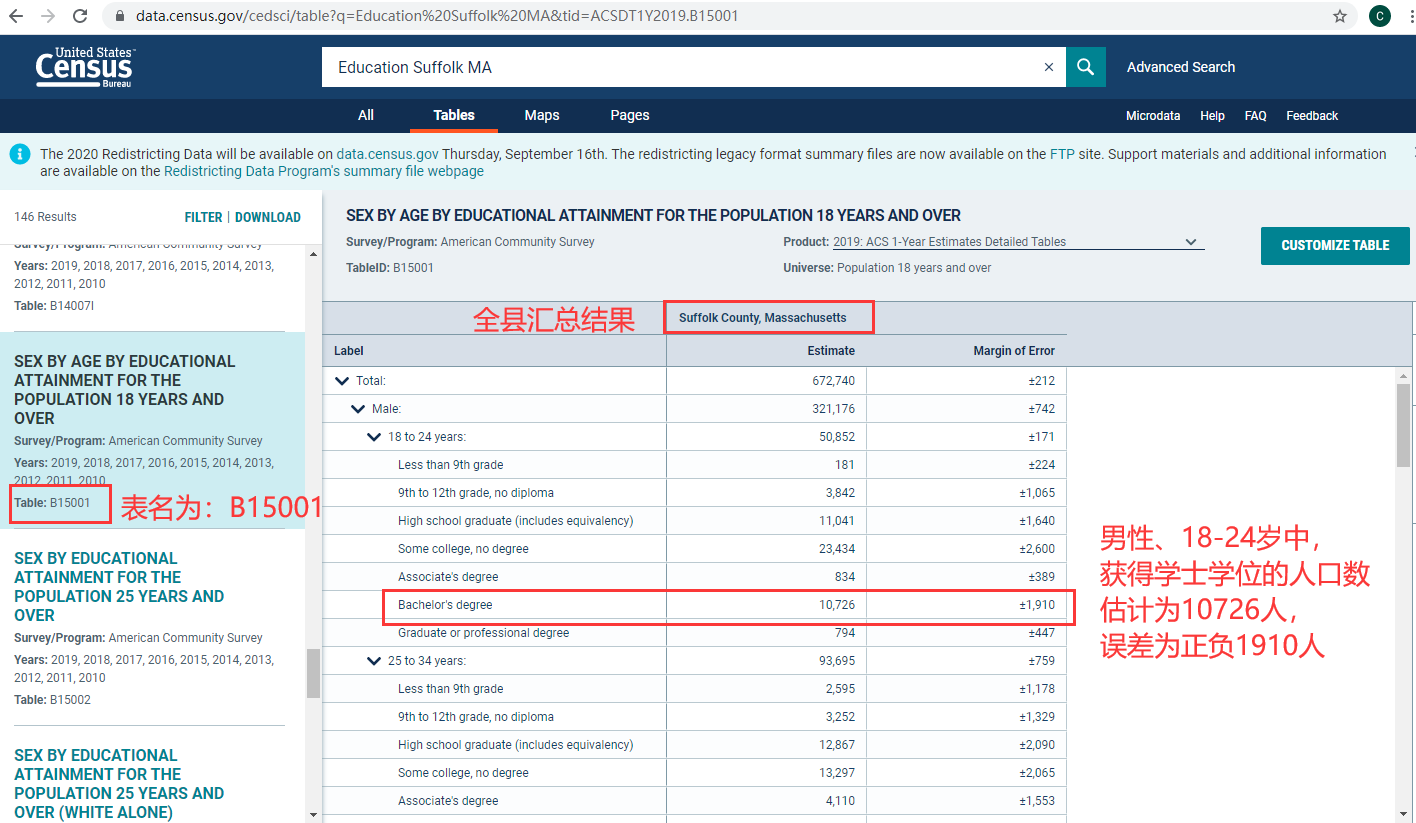
如果想看各个Tract的统计结果,可以用Filter工具。这个工具的效果也可以在一开始搜索时使用高级搜索(Advanced Search)实现。在上图左侧表格选择栏的右上角找到“FILTER”,点击后打开筛选工具,如下图所示。图中展示了利用Geography筛选工具找到指定Tract的方式。可以选择所有Tracts,但是这样的话会报告“表格太大,无法显示,只能下载”。所以,这里就只选择了1001、1002、1003这3个Tract作为例子。此外,也可以通过Years等其他筛选工具做其他方面的筛选。
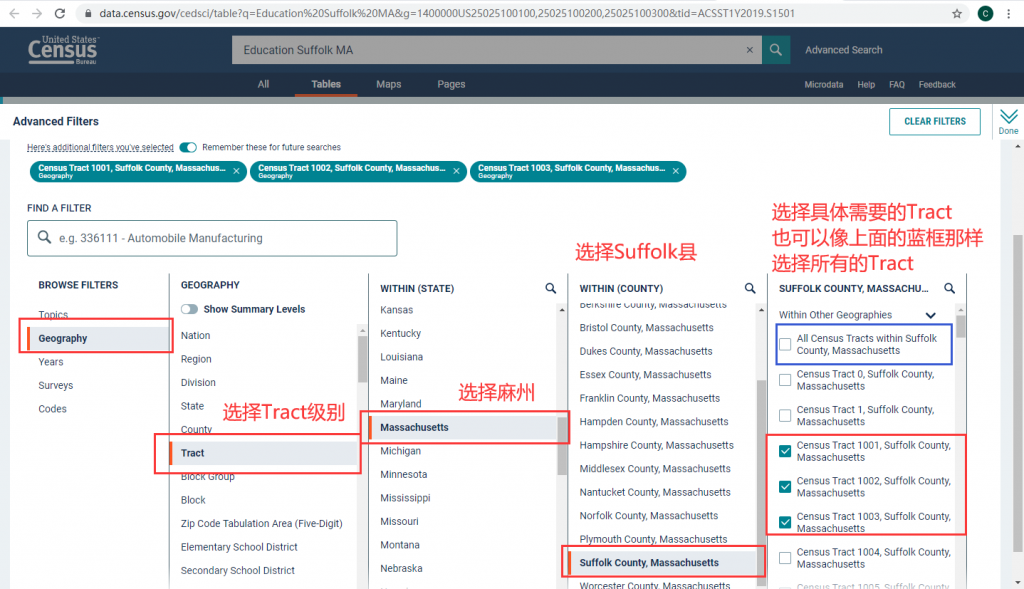
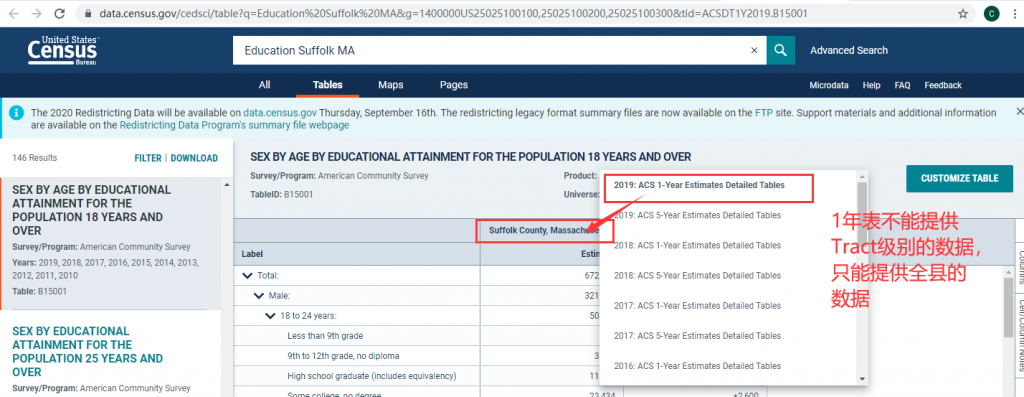
筛选完成后点击右上方的“Done“,回到表格页面,然而会神奇地发现没有任何变化,这是因为我们选择的空间单元太小,不支持该数据。看一下标题栏中的Product,写着“2019 ACS 1 Year Estimates Detailed Tables”,表明这个表是2019年的数据,而且是最近1年的平均数据。ACS分1年表(1 year)和5年表(5 year)表两种产品。如果一个空间统计单元的人口数比较多(好像是超过6400人),那么就有足够的样本供每年一次不重样的抽样,就会有1年表可用;反之,对于那些人口比较少的空间单元,为了避免频繁地敲开同一家门,就不会每年都更新,而是5年更新一次,这样的地方就只有5年表可用,反映的是最近5年的平均估计值。虽然1年表更具时效性,但是由于小的空间单元没有1年表,所以感觉5年表在我们的研究中用得更多。
这里既然在Tract级别没有1年表,我们就把它改为5年表,改好之后,数据就出来了。往右边拉一下,就能看到我们指定的3人Tract在不同性别、年龄段上的教育程度分布了。
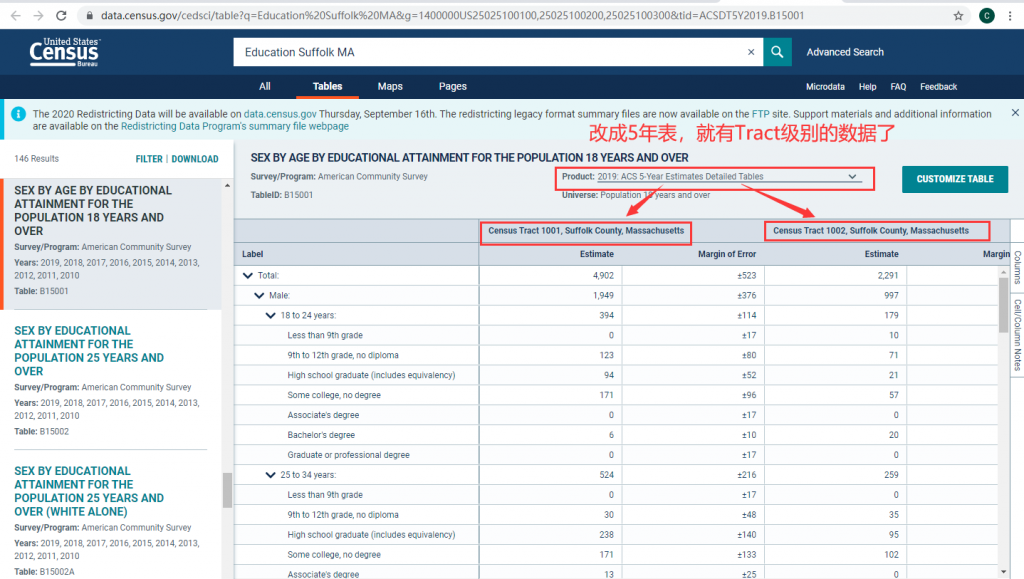
这样就完成了,可以说十分的直观舒服,几乎没有任何难度。该表格应该可以直接下载,Filter旁边有Download。
基于原始数据
再次重申:不推荐直接处理原始数据,除非已经习惯了这些我觉得别扭的格式。不过,这一节里详细讲述了原始数据组织结构,在用第三方模块获得数据时也是需要对此有所了解的。
首先我们要下载原始数据。搜索ACS Summary Files,或者在ACS的导航栏里找Summary Files,找到这个网页:https://www.census.gov/programs-surveys/acs/data/summary-file.html,往下拉,选择年份,会看到1年数据或5年数据的FTP下载链接。其实无论点哪个,都会进入一个统一的FTP资源管理器中,里面即有1年数据,也有5年数据。我们就像上面一样,统一用5年数据。
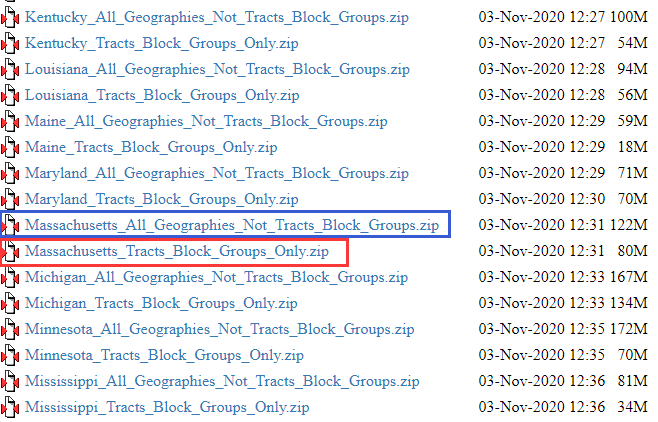
点击这个FTP链接之后,可以看到如下左图的内容。最下面的2个是模板文件,一个是面向1年数据的,一个是面向5年数据的,我们要把下面那个5年数据的模板文件压缩包(2019_5yr_Summary_FileTemplates.zip)下载到本地。模板文件很重要,作用以后再说。上面是按不同方式归档的数据内容文件夹,这里选择”5_year_by_state“,即按州选择文件压缩包,进入右图的界面。找到麻州的文件,会发现有2个,下面红框中是是”Massachusetts_Tracts_Block_Groups_Only.zip”,即专门针对Tract和Block Group级别的数据,上面蓝框中的是“Massachusetts_All_Geographies_Not_Tracts_Block_Groups.zip”,即其他各种空间统计单元的数据,即包括Tract上级的数据,也包括各种其他系统空间单元的数据。既然我们要Tract级别的数据,那我们就选择下载下面的文件。这样,我们就有了数据内容文件压缩包和模板文件压缩包,各自解压待用。
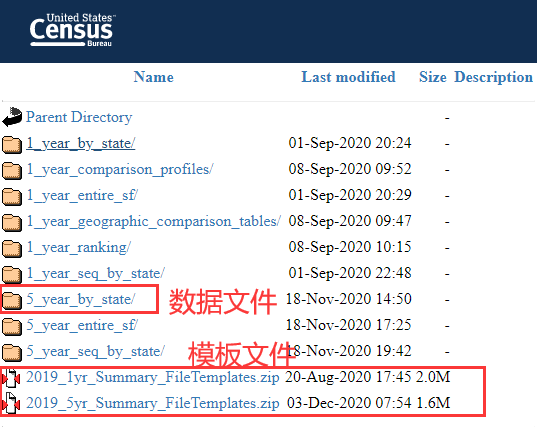
数据文件解压后如下所示。这里包含很多文件,分为三类。
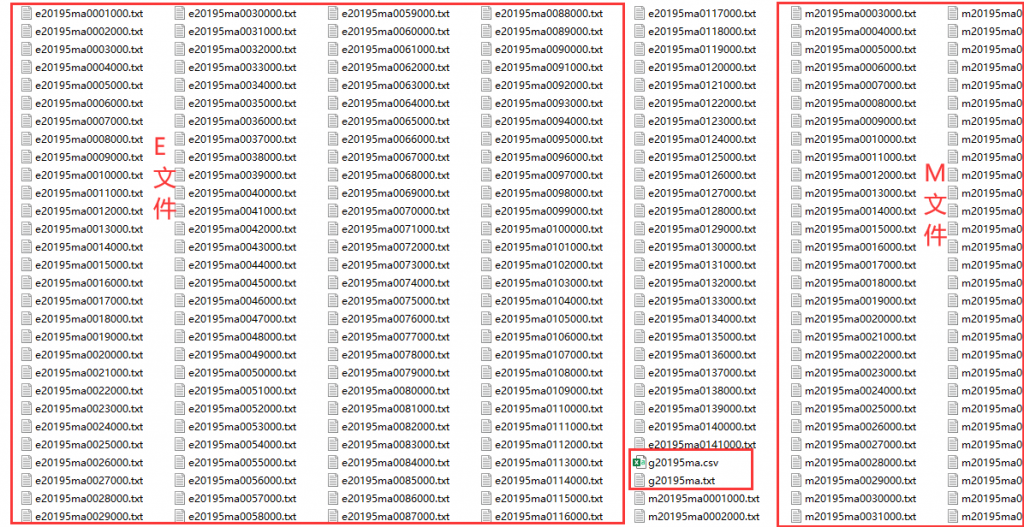
- 第一类是以e打头的,从e20195ma0001000.txt到e20195ma0141000.txt,简称E文件。这些文件是统计结果的估计值,是我们最后要用的数据,其文件命的命名规范参见这里的P18表2.5:其中,E代表estimation,即统计结果估计值;后面的2019代表是2019年的数据;再后面的5代表是5年数据(如果是1年数据,则写作1);再后面的ma是麻州的简写;再后面的4位数字(从0001到0141)很重要,被称为序列号(Sequence Number),是找到正确文件的关键,具体怎么用后面再说;最后的三位都是000,是为未来留的编码。显而易见,E文件最为重要,每次处理数据就要挑一个E文件。
- 第二类是以m打头的,与上面的E文件一一对应,只是把前面的字母从e换成了m,表示margins of error,所以这些M文件就是统计结果的误差值。像上面说的学士及以上学位的比例为48.2%±1.1%,那么48.2%就在E文件里,1.1%就在M文件里。不过,如果不太在意误差的话,M文件就用不到了。
- 第三类就2个,是g20195ma.csv和g20195ma.txt,这两个文件的内容是一样的,只不过格式不一样,它们是地理信息数据文件,也是每次必须要用的。
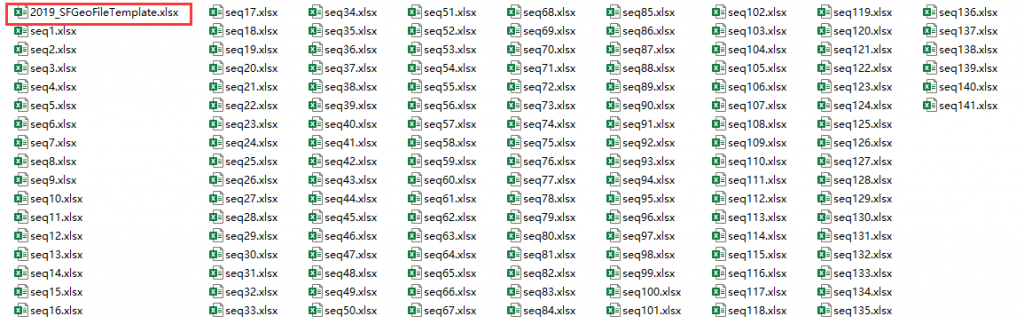
再看一下模板文件夹,里面的文件如下所示。第1个文件叫2019_SFGeoFileTemplate.xlsx,它是与上面的地理数据文件(g20195ma.csv/.txt)相对应的地理模板文件。后面的文件是数据模板文件,它们都是以seq打头,从seq1.xlsx到seq141.xlsx,这里的seq就是指上面说到的序列号(Sequence Number),后面的三位数字与上面的E文件/M文件中的序列号一一对应。例如,如果我要处理的是e20195ma0088000.txt这个数据内容文件,那我就要找seq88.xlsx这一数据模板文件。
了解了这些原始数据的构成以后,就需要明确一点:要获得任何一个信息,都要同时用到4个文件:
- 数据内容文件:在上面所说的E文件中找一个包含所需要的信息的文件,当然,如果你是分析误差的,那就去找M文件。
- 数据模板文件:跟E文件的序列号相同的一个名为Seq***.xlsx的文件。
- 地理文件:混在一堆E文件中,形如g20195ma.csv/.txt的文件
- 地理模板文件:混在一堆seq文件中,形如2019_SFGeoFileTemplated.xlsx的文件。
我们可以以下面这张国内统计年鉴的表格结构为参照,说明这4个文件都在发挥什么作用。数据内容文件是没有表头的,只是纯粹的数字结果。于是当不熟悉的人第一次点开那一个一个的E文件时,虽然隐约感觉每一列是一个属性,但是满屏都是数字,完全不知道是啥意思。而模板文件就类似于表头的作用,当然略有一点点差异。数据模板文件有2条,第一行是真正的表头,但是都是编码化的,比如说B15001_001,单看它依然不知道是啥,第二行则是解释,到这里终于知道每一列是啥了。序列号相同的数据内容文件和数据模板文件的列数是严格一致的,所以直接把数据模板文件的第一行作为表头放到数据内容文件的上面就行了。另一方面,地理文件提供了空间单元的信息。而地理文件同样是没有表头的,它的表头由地理模板文件所提供,地理文件和地理模板文件的列数与是严格一致的,直接上下合并在一起就可以了。但是,需要注意的是,虽然数据文件的每一行对应一个空间单元,但是地理文件和数据文件的行数不一定相等——别忘了,除了这个只针对Tract和Block Group级别的数据文件外,还有针对其他空间单元的数据单元,而地理文件可是包含了所有可能的空间单元的。所以,加了表头的地理文件和加了表头的数据文件没法简单地左右拼在一起,需要依赖一个关键词——LOGRECNO,它代表Logical Record Number,同时在数据文件和地理文件中作为一列存在,就是用来合并的。
还有一个问题是:怎么找到所需要的E文件和对应的数所模板文件呢?比如说现在,我要获得教育相关的信息,那里有141个E文件和对应的模板文件,我怎么知道正确的序列号是多少?同时,一个文件打开后有非常多列,虽然模板文件中有解释每一列的意义,但是我怎么能提前知道我要的列在哪里呢?要回答这些问题,就需要搞清楚表名与序列号的关系了。
前面我们已经看到了表名了例子了——B15001。这里的B代表Base,是指基础表、详细表(Base或Detailed),除了B还有S、DF等其他字母,代表别的表类型,但根据我的经验,大多数情况下找B表就够了;后面的两位数字15是大类主题(subject);再后面的三位数字001是subject=15下面的子类主题(topic)。现在有的表名最后还会加一个字母,用于代表该表是针对特定种族的结果。具体的表名命名规范参见这里的P20,图3.1。总之,一个表名就对应了同一个主题下的统计结果。表里的各个属性也有属性名,就用“表名_行号“表示。比如,B15001这张表是分性别*年龄的受教育程序统计表,它下面分了83个类别,即对应了83个属性,编号从B15001_001到B15001_083,其中,B15001_009的意义是18-24岁获得学士学位的男性人口数。这些属性名正是数据模板文件中的表头列名,后面如果采用第三方模块下载数据,也需要指定这些属性名。
那么怎么才能知道都有哪些表名,每个表里有哪些属性名,每个属性名是什么意思呢?当然不用去一个一个地翻模板文件中的解释。打开ACS Summary Files的网页(https://www.census.gov/programs-surveys/acs/data/summary-file.html),找到下面的Summary File User Tools,第一个提供的就是的Table Shells(xlsx文件),即表格布局结构。可以点击这里下载2019年的版本,在Excel中打开就可以看到,它详细列出了各个表名、表中的属性名,以及对应的解释,如下所示。我们可以搜索Education,这里会找到不少内容。我们不难找到B15001这张表,然后看到它下面有B15001_001到B15001_083这83列,于是我们就知道了所需要的表名和属性列名。

那为什么会有序列号呢?因为一张表装不下。可以想像ACS数据是一张大表,每一行是一个空间单元,每一列是一个属性。现在,光B15001这张表就占了83列属性,再看看Table Shells文件,可了不得,有4万多列?!所以这表也太大了,必须分段。然而,美国人又不想每一张表一个文件,于是就分成了不同的序列(Sequence),一个Sequence里包含了多张表。每个Sequence是不是完整覆盖一个Subject或一个Topic,我没有研究,但这并不重要。我们只需要根据所需要的表名,查找它在哪个Sequence中就行了。
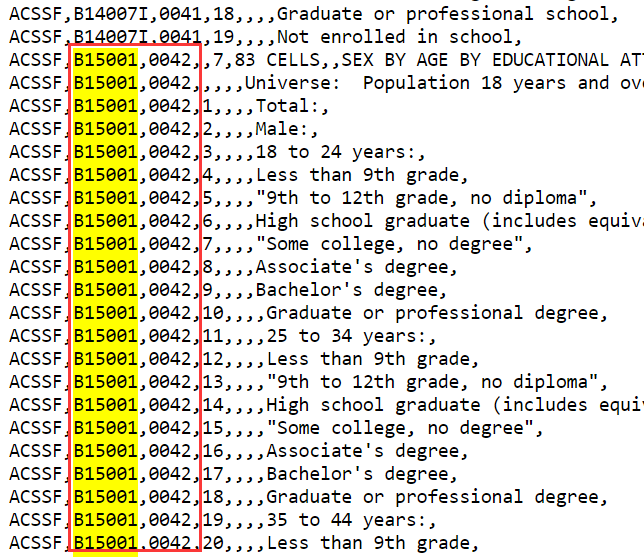
怎么查?还是在上面说的ACS Summary Files的网站里(URL在此),还是找下面的Summary File User Tools,第二个提供的是Sequence Number/Table Number Lookup File,即序列名/表名查询文件,有多种格式(.sas、.csv、.txt)。我们打开txt格式文件,在这个网页里。直接搜索我们的表名B15001,结果如右图所示。我们再看到了表名、行名及意义。表名右侧一列即为序列号,显然,所有属于B15001表格的属性列都在序列号=0042的文件里,那我们就去找e20195ma0042000.txt这个数据内容文件以及seq42.xlsx这个数据模板文件就行了。
相比于国内统计年鉴中省——市——县的空间单元,ACS的空间单元要丰富的多。下图截取自Census Bureau
这样就基本完结了。再回顾一下全部步骤(假定我们已经下载好了全部文件):
- 根据研究需要,通过查找Table Shells,明确表名和属性名。
- 通过查找Sequence Number/Table Number Lookup File,明确序列号。
- 根据序列号,找到所需要的数据内容文件(E文件)和数据模板文件。
- 打开数据内容文件和数据模板文件,利用后者为前者添加表头。
- 打开地理文件和地理模板文件,利用后者为前者添加表头。
- 按行合并地理文件和数据文件,合并的关键列为LOGRECNO。
- 上一步得到的全部空间单元的结果,如有需要,再筛选出特定的空间单元
上面4-7步的Pandas操作参见这个Jupyter Notebook。可以看到,所得到的结果与前面Explore Census Data的完全相同。当然,也可以不写代码,完全用Excel操作,我记得ACS网站上有教程。
使用synthpop模块
最后这种方式是我们在研究中实际采用的,即通过Python的第三方模块synthpop进行下载。不过,在此之前需要大致了解ACS数据的基本构成方式,至少知道表名是什么样的,属性名是什么样的,以及怎么去确定所需要的属性名,具体可以参照这里。下面就假设我们已知道知道所需要的属性名是B15001_001到B15001_083。
synthpop模块是用来人口合成的(具体参见这篇),所以属于同一个生态。synthpop中专门提供了census_helper这个子模块,帮助处理ACS数据和下面的PUMS数据。它的基本原理是调用另一个库census,然后根据API的规则将用户输入的搜索条件(州、县、Tract、Block Group、年份、属性列等)转化为URL,然后向服务器请求数据,简单处理后返回。
要想使用该功能(包括census模块的功能),首先需要注册一个Census Bureau的Key,网址为https://api.census.gov/data/key_signup.html。根据我的经验,申请Key是免费的,毫无难度的,使用Key也是没有限制的。所以果断申请吧。只要填个邮箱,就会发到邮箱里,收到后激活一下就好了。我暂时用的Key是:7a25a7624075d46f112113d33106b6648f4268dd,最后2位改掉了。
使用时,首先导入模块,然后利用Key生成一个Census实例,命名为c。
然后需要明确下载的空间单元——州、县、Tract之类的。这里的州、县需要采用FIPS编码,即Federal Information Processing Standards。该编码体系下,美国的每个州都是一个两位数字,麻州的编码为25。县的编码是3位数字,Suffulk县的编码为025。如果不知道,那就google,很容易查到。另外,我们已经知道了所需要的列属性是B15001_001到B15001_083,需要特别注意的是,在写属性名时,要在后面带个”E”,表明要请求的是该属性的估计值,而不是误差值(“M”)。所以,这里的属性名是B15001_001E到B15001_083E。
接下来只需一条命令即可。由于我们要的是Tract级别的数据,所以调用Census实例(c)中的tract_query()方法,它要求的参数包括属性列(census_columns),州(state),县(county),年份(year),以及Tract。我们先把Tract设为None,即要求返回该县下面的所有Tracts。
返回的结果中,会自动带上NAME属性,即结构化的地名。既然我们是3个Tracts,那最后再按NAME筛选一下就行了,如下所示。不过实际中,很少需要这么干,因为既然用了这种方法,那一般就是批量处理所有Tracts数据了。
结果如下,与之前Explore Census Data的结果完全一样。
| NAME | B15001_001E | B15001_002E | B15001_003E | B15001_004E | B15001_005E | B15001_006E | B15001_007E | B15001_008E | B15001_009E | ... | B15001_074E | B15001_075E | B15001_076E | B15001_077E | B15001_078E | B15001_079E | B15001_080E | B15001_081E | B15001_082E | B15001_083E | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 94 | Census Tract 1003, Suffolk County, Massachusetts | 3350 | 1171 | 161 | 0 | 0 | 138 | 23 | 0 | 0 | ... | 25 | 33 | 366 | 76 | 55 | 175 | 36 | 0 | 0 | 24 |
| 167 | Census Tract 1002, Suffolk County, Massachusetts | 2291 | 997 | 179 | 10 | 71 | 21 | 57 | 0 | 20 | ... | 13 | 35 | 163 | 53 | 26 | 43 | 19 | 11 | 11 | 0 |
| 189 | Census Tract 1001, Suffolk County, Massachusetts | 4902 | 1949 | 394 | 0 | 123 | 94 | 171 | 0 | 6 | ... | 186 | 40 | 496 | 142 | 85 | 136 | 77 | 36 | 20 | 0 |
另外,如果我们是要下载Block Group级别的数据,可以用下面这个方法,参数跟上面的tract_query()都差不多,不言自明。
还有一种特殊情况:有些属性在Block Group级别没有——原因可能是因为误差太大,于是就提供了——只有在Tract级别上才有。可是,我们做人口合成或其他什么事的时候,还是想在Block Group上做,怎么办呢?可以用下面的block_group_and_tract_query()方法去Hack。该方法的原理是:用户分别指定Block Group级别可获得的属性以及仅在Tract级可获得、Block Group级别不可获得的属性,然后分别下载2张表——Block Group表和Tract表,再试着阗2张表合并(按照州+县+Tract的地名),合并后,将仅在Tract中可用的属性按比例分配到Block Group中去,这个比例Block Group的规模除以Tract的总规模。比如下面的代码中,作为Block Group规模的列是B11001_001,是按有没有孩子去分的家庭数量,作为Tract Group规模的列是B08201_001,是按有几辆车去分的家庭数量,这个数据在Block Group里是没有的。虽然是基于不同的维度,但反正两个都是家庭总量,那么就可以做比例了。在没有别的办法的情况下,这种黑科技是行得通的。
重分类
不管用上面哪种方式得到了ACS数据,许多情况下,我们都需要进行重分类。一方面,原始数据的分类体系可能不适合我们的需要;另一方面,至少也需要把原来这些没有意义的属性名变得有实际意义。此时,我们可以使用synthpop模块中的分类辅助函数catergorize()。
下面的代码以这篇人口合成文章中的家庭ACS数据为例演示重分类的处理。categorize()函数接受2个必选变量df和eval_d,以及一个可选变量index_cols。df是需要处理的数据表,格式跟我们刚才获取的数据格式一样。eval_d是一个体现处理方式的大字典,它的每个key是一个二元tuple,其第一个元素是重分类的维度名称,第二个元素是重分类的类别名称;对应的value是一个字符串,以原始数据列名和加减乘除等运算的形式指定了运算操作,并把操作结果作为该维度名称下的该类别。例如,(“income”, “lt35”): “B19001_002E + B19001_003E + B19001_004E + B19001_005E + B19001_006E + B19001_007E”的意思就是,执行value中的操作,把原数据中B19001_002E到B19001_006E + B19001_007E各列加起来,把结果作为Income(收入)维度下的lt35(小于3.5万)类别。当然,eval_d字典中还包括了计算Income维度下的其他类别——gt35-lt100,gt100,以及car(小汽车数量)维度下的none、one、two or more三个类别。
返回的重分类之后的数据表中,列索引将是个二维索引。外层索引即为上面所说的维度(income、car),或者称为类别名称;内存索引即为上面说的具体类名,或者称为类别取值。重分类之后的数据表长下面这个样子,这就是在人口合成的文章中用于下一步处理的数据。
| cat_name | cars | income | ||||
|---|---|---|---|---|---|---|
| cat_value | none | one | two or more | gt100 | gt35-lt100 | lt35 |
| NAME | ||||||
| Block Group 2, Census Tract 5172, Wayne County, Michigan | 51 | 94 | 20 | 52 | 100 | 16 |
| Block Group 1, Census Tract 5172, Wayne County, Michigan | 202 | 370 | 81 | 129 | 218 | 308 |
| Block Group 1, Census Tract 5207, Wayne County, Michigan | 319 | 278 | 125 | 55 | 179 | 490 |
| Block Group 2, Census Tract 5207, Wayne County, Michigan | 489 | 426 | 191 | 167 | 382 | 558 |
| Block Group 1, Census Tract 5238, Wayne County, Michigan | 38 | 121 | 96 | 0 | 149 | 108 |
PUMS数据
概况
PUMS是Public Use Microdata Sample的简称,即面向公共使用的微观数据样本。PUMS其实也是ACS系统下的一个数据产品,而上面所说的ACS准确地说是其中的summary files。所谓的微观数据样本,就是PUMS会给我们若干个人或家庭,告诉我们每个家庭、每个人都有哪些属性,可以说是最原始的数据。只是,PUMS的抽样率更低,且空间统计单元与前面ACS的不一致。
由于是跟着ACS调查走的,所以PUMS也是每年都有, 而且也分1年数据和5年数据。PUMS也是按州提供,会同时提供两个压缩问件:一个是家庭(household)级别,每个样本(每一行)对应一个家庭;另一个是个人级别,每个样本(每一行)对应一个人。麻州2019年家庭级别PUMS数据样例如下所示。表中第一列的RT表示数据类型,H代表家庭,P代表个人,这里当然都是H,SERIALNO是家庭的编号,主要用于家庭表和个人表的链接;PUMA是空间统计单元;ST是州的FIPS编号,麻州为25。再后面的就是各个具体属性了。与ACS数据那种毫无意义的编码名称相比,这里的属性名称大多是首字母的缩写,观感上好一些。
| RT | SERIALNO | DIVISION | PUMA | REGION | ST | ADJHSG | ADJINC | WGTP | NP | ... | WGTP71 | WGTP72 | WGTP73 | WGTP74 | WGTP75 | WGTP76 | WGTP77 | WGTP78 | WGTP79 | WGTP80 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | H | 2015000000003 | 1 | 303 | 1 | 25 | 1079106 | 1080470 | 0 | 1 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | H | 2015000000173 | 1 | 3304 | 1 | 25 | 1079106 | 1080470 | 14 | 2 | ... | 16 | 13 | 19 | 5 | 12 | 6 | 15 | 11 | 5 | 4 |
| 2 | H | 2015000000185 | 1 | 300 | 1 | 25 | 1079106 | 1080470 | 27 | 1 | ... | 46 | 27 | 21 | 24 | 46 | 8 | 7 | 7 | 7 | 26 |
| 3 | H | 2015000000196 | 1 | 506 | 1 | 25 | 1079106 | 1080470 | 18 | 3 | ... | 19 | 30 | 5 | 18 | 18 | 5 | 17 | 17 | 5 | 28 |
| 4 | H | 2015000000239 | 1 | 4700 | 1 | 25 | 1079106 | 1080470 | 10 | 2 | ... | 3 | 9 | 15 | 9 | 3 | 3 | 10 | 9 | 3 | 8 |
如何才能知道每一列到底是啥意思,以及相应地,如何查找自己所需要的属性呢?在这个PUMS Documentation页面里,可以找到每一年PUMS数据的各种帮助文档,其中,最重要的是下面的PUMS Data Dictionary,提供了不同格式的解释说明。打开PDF文件,如右图所示。这里的例子是属性名SCHL,可以看到,它的取值为2个字符,其意义是教育成就。取值为bb代表了小于3岁,不适用该属性;取值从01到24代表了从没上过学到博士学位,共计24个等级的受教育程度。这个Data Dictionary是按字母顺序排列的,里面包括了所有家庭表和个人表的属性解释。需要找哪个属笥时,搜索一下就OK了。

PUMS数据的空间统计单元不是前面ACS的那些,而是独立的PUMAs,即Public Use Microdata Area。PUMA每10年更新一次,所以2019年时我们一般会用puma10,即2010年的版本,现在可能已经有puma20了。根据设计,一个PUMA的人口规模为10万人,所以PUMA的尺度一般远大于Tract和Block Group。PUMA的编号只在州内有效,共包含5位数字,其中,同一个县的PUMA前三位数字相同。之所以说州内有效,是指不同的州可的PUMA可能相同,所以,要想定义一个全美唯一的PUMA,可以用7位数字,即前2位为州编码,后5位为PUMA在州内的编码。
PUMA与Tract、Block Group之间是具有对应关系的。我们可以用synthpop中census_helper的Census实例(参见这里)去帮助查询。例如,如果h_acs和p_acs是我们获取的有关家庭属性和个人属性的ACS普查信息表,每一行对应一个ACS空间统计单元,那么,我们可以用下面的代码得到每一行对应的PUMA编号。
数据获取方式
PUMS数据的格式比上面的ACS数据简单多了,获取方式也相对简单。主要用2种:(1)直接下载;(2)通过第三方库synthpop下载。
对于直接下载的方式,进入PUMS数据的下载页面:https://www.census.gov/programs-surveys/acs/microdata/access.html,下方的Access on FTP site中有1年数据和5年数据的选项,点击进入后,就可以看到按州分的数据压缩包。其中,h打头的是家庭数据,p打头的是个人数据。例如:csv_hma.zip以及csv_pma.zip就是麻州的格式为csv的家庭和个人数据。
用synthpop也很简单,依然是用上面说的census_helper的Census实例(参见这里)。我们只需要指定要下载的属性名列表,然后指定州和PUMA编码就可以了。注意,州是2位数字,PUMA是5位数字。代码如下所示。
重分类
与ACS数据一样,PUMS数据一般也需要重分类。而且,如果是做人口合成的话,PUMS数据的类别设定需要与ACS数据保持一致。
我们一般需要定义一些重分类函数,其输入的是PUMS数据的一行,然后在函数内部根据对行中某些属性列的操作完成重分类,例如,下面的代码就将原数据中的AGEP属性重分类为了age。
此外,由于人口合成中需要保持普查数据和微观数据的分类体系一致,synthpop的分类辅助包categorizer中也附带提供了重分类功能,其位于joint_distribution()函数中。该函数的具体用法参见这篇关于人口合成的文章中“获取联合分布“的部分。简单地说,这个函数要求的第一个参数是微观数据样本表,即我们的PUMS数据;第二个参数是分类表,一般是基于普查数据得到的,也是最终要将微观数据重分类的目标类别。第三个参数,mapping_functions,是一个可选参数,用来定义重分类的方法。人口合成的文章中,我们是假定普查数据和微观数据都已经分好类了,而且两者类别是一致的,所以就不需要这第三个参数了。而实际中,我们可能是先处理完了ACS普查数据,完成了重分类,现在手里的是刚刚下载好的PUMS数据,还都是原始的属性,那么我们就必须传递第三个参数,指定要对PUMS做哪些重分类,才能使其分类结果与普查数据一致。
于是,当PUMS数据是原始数据时,人口合成的文章中“获取联合分布“的这部代码将写成这样的形式。重点是在5-9行的mapping_functions,它是一个字典,共keys是重分类后生成的新列表,values是每一个key对应的重分类函数,就是形如上面的age_cat这样的输入一行数据,输出该行对应的结果的函数。
到此为止,应该一切都讲清清楚了。