一般的线性回归中有很成熟的残差分析与奇异/强影响样本检测手段,而Logit模型中却很少有人提及。
想到这个话题是因为在Stata中,看到Logit模型的后估计(post-estimation)工具里提供了一些有意思的指标,就想试一试,包括:残差(rit),标准化残差(rsit),杠杆值(leverage/hat: hit),欠拟合指标(lack of fit: Δχ2it),系数影响指标(influence: Δβit)。下标中,i代表某次选择,t代表该次选择的某个选项。这些指标的意义在于:1)找出哪些样本难以被现有模型解释,拟合得比较差,提示这些样本的选择机制可能与主流有较大不同;2)找出哪些样本对于模型系数的影响比较大;3)基于前两点,能否借助这些指标把样本分为多个组别,每一组的选择偏好相似。
Stata官方文件对这些指标的计算是基于Hosmer Jr. & Lemeshow在2000的专著“Applied Logistic Regression” (Page 248-251),下面简述一下计算公式。有一点需要注意的是,选择模型一般使用长表形式,有NALT个备选项,则有NALT行共同构成一次选择,其中每一行以0/1表示一个特定的备选项是否被选中,上述指标都是以每一行为单位计算的,而不是以每一次选择的NALT行为单位。
残差rit的计算非常简单:对于每一次选择的每一个选项,其实际是否被选中yit(0/1)与模型预测的被选中概率θit之差,再除以θit的平方根。前面的差值就等同于一般线性回归的残差,除以θit的平方根是因为这是一个卡方统计量,算过卡方检验的应该都明白,也正因为如此,这个残差被称为Pearson残差。

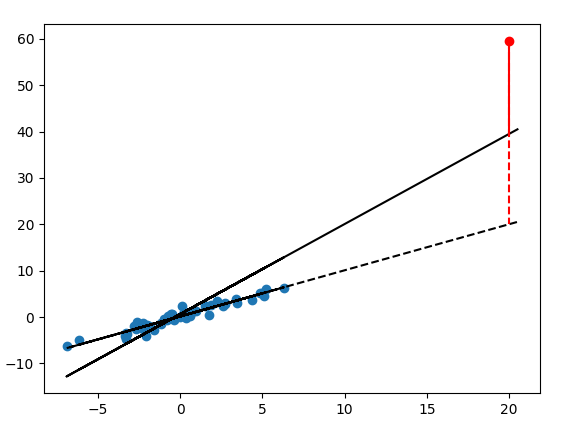
但这样的残差其实是有问题的,因此需要计算标准化残差。问题在于:如果真的有偏离很大的样本,这些样本可能已经把模型系数扭曲了——让模型系数朝着自己有利的方向偏离,导致其残差被低估。这个问题在一般的回归可以直观地反映出来:下图中,黑虚线才是蓝点应有的拟合结果,然而红色异常点的存在使得实际的回归线成了黑实线,被异常点带偏了,导致了该异常点的残差虽然不小(红实线),但仍然被低估了(红实线+红虚线)。Logit模型里也是同样的道理。
因此,标准化残差要考虑每个点对于模型结果的“扭曲程度”,对残差进行扩大修正。这个扭曲程度用 杠杆值hit测度(0~1),其值越大,则撬动整个模型的杠杆效应越大,扭曲程度越强。标准化残差rsit等于rit除以1减hit的平方根——扭曲程度越强,认为残差越被低估。
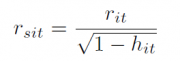
欠拟合指标(lack of fit: Δχ2it)就很简单——标准化残差(rit)的平方,消除残差的正负性,它反映了如果某一行记录被剔除,那么模型整体的Peason卡方值能减少多少。在此基础上,系数影响指标(influence: Δβit)是用欠拟合指标乘以杠杆值的一个变形形式,反映了如果某一行记录被剔除,那么模型估计系数在理论上有多大程度的标准化的变化。
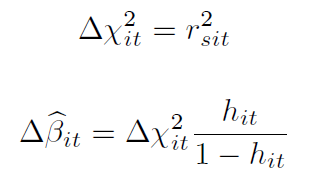
系数影响指标反映了一个经典理论:对系数的影响 = 差异程度 × 影响力。这里所说的差异程度主要指模型系数β的不同,即给定同样的自变量X,得到的结果与主流差异很大,这实际上就是反映了选择机制的不同;而影响力就是刚才所说的杠杆值,主要指的是自变量X的不同,如果一个样本的X与其他样本差得很大,就是高杠杆样本。还是用一般回归作类比,下图中,(a)中的β虽然有足够的差异程度,但X的杠杆影响力不足以影响整体的回归结果;(c)中的X比较远,杠杆影响力大,但与整体的趋势是一致的,即β没有太大差异,自然也不会影响整体的回归结果;只有(b)中β的差异程度也大,X的杠杆影响力也大,因此导致回归结果出现较大偏差。换言之,如果一个样本对系数的影响很大,必须同时满足两个条件——该样本中,自变量对因变量的影响机制特殊,且该样本的自变量本身也特殊。

这里引出一个有意思的问题。朱玮老师之前提出了通过逐个剔除样本,观察模型系数变化的方式,找出一组样本中选择机制不一样的样本,从而将样本按选择机制分为不同的组。我以前也有类似的想法,但没有想清楚具体怎么操作。我不清楚朱老师方法的细节,但至少有两点可以明确:1)没有必要真的一个样本一个样本地剔除后重新估计新模型(如果有NCS次选择,这样就要拟合NCS个模型),虽然也花不了多少时间,但这里有更便捷的方法可以直接估计系数的变化;2)最适宜的指标其实不是系数的变化,因为如(a)图所示,这个方块点显然具有完全不同的作用机制,但由于它的X的杠杆影响力较低,其实并没有太影响到模型估计的结果,剔除与否系数变化不大,有可能被误分类,那么,既然我们想要找到(a)或(b)这样的点,而不是(c)那样的点,最适宜的指标显然是经过修正后的标准化Pearson残差(rsit)或者欠拟合指标(lack of fit: Δχ2it)。
最后要说一下杠杆值是怎么求的,这是坑了我挺久的问题。原文中这样写道:

你会发现如果xit真是一个行向量的话,维度怎么也不对。试了好几次,终于确定了正确的算法:首先,对于每一组样本(NALT行),把它们的自变量都各自减去自己这一组的加权平均值(权重为每个备选项预测的选择概率)做去中心化,得到xit,然后,把所有组的xit拼在一起,得到一个大矩阵X-tilde,其维度与原始的X相同。U是所有选择中所有选项的选择概率的对角矩阵,因此对于NVAR个自变量的数据,中间那个逆矩阵的维度就是NVAR*NVAR,然后我们把每一次选择中每一个选项的xit看成列向量(不是行向量),转置后与它对应的预测选择概率相乘,再乘以这个逆矩阵,再乘以自己,就得到本次选择本选项的杠杆值了……
下面是在python中的计算过程,测试后与Stata计算的结果完全一样。X是长表形式的自变量,data是包含X的DataFrame,model是用pylogit包对data进行估计得到的模型object,res是残差,hat是杠杆值(其中,X2是对本组内部的加权平均值去中心化的结果,middle_term是中间那个逆矩阵),stdres是标准化残差,dx2是欠拟合指标,dbeta是系数影响指标。

这样都算好之后,注意到Logit模型不是一行一个样本,而是多行一组对应一次选择,计为一个样本。因此,我们可以简单地将一组中多行的指标加起来,作为这一次选择总体的误差/杠杆/欠拟合值/系数影响值。
下面就以随机模拟的数据来看看这些指标的情况。
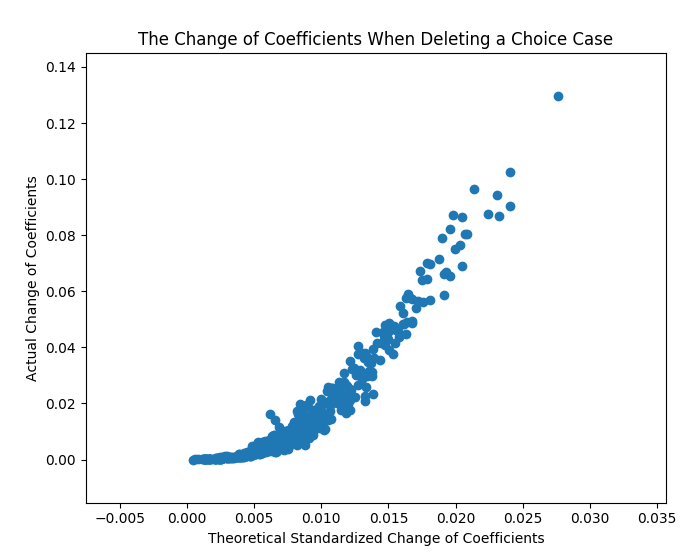
首先来比较一下,通过这种残差分析算得到系数影响指标与实际真的剔掉一个样本后系数的变化值之间的关系。假设有10个变量,5个备选项,500次选择,对比结果如下图。横坐标是是每次选择的系数影响指标(influence: Δβit),是系数变化的理论值和标准化值,纵坐标是分别拟合了500个删样本数据得到的系数的实际变化。可以看到,二者虽不是精确的线性关系,但是正相关性是明显的。我们可以断定:系数影响指标(influence: Δβit)确实准确地反映了单个样本对整体模型系数的影响程度。
下面来看一看不同类型的异常样本能否被正确地反映出来。我们生成1000个正常的选择情景,每个选择情景包括2个选项,由2个自变量进行解释。然后,第1001个样本采用恰好相反的系数,但是自变量X的分布与群体相同;第1002个样本采用与群体相同的系数,但是自变量X的尺度被放大了20倍,造成很强的杠杆影响;第1003个样本将前两种方式结果,既采用相反的系数,也放大了X的尺度。
下图是指标的估计结果:欠拟合指标排名前2位的是1003号和1001号,因为它们采用了相反的系数,所以其选择结果难以被通用模型解释,特别是第1003号,由于X被放大,其结果差得更大;杠杆值排名前2位的1003号和1002号,它们都是由于X的分布与群体差别很大造成的,第3名556号的杠杆值就小得多了;对于系数影响指标,第1位是1003号,其值比第2位高很多,而1001号与1002号都没有出现在前3,它们一个是只异常但影响力低,一个是影响力高但正常,所以都不会对拟合结果产生太大影响。
。
经过多次实验可以发现:系数影响指标具有很好的参考价值,能够比较可靠地发现潜在的样本问题。该系数取值高时,说明对应的样本的选择决策机制比较特殊,同时该样本的自变量分布也不同于大多数样本,应当考虑数据录入错误,问卷答题不认真严谨,该样本本身比较奇怪等问题,甚至可能要考虑把它从数据集中剔除。
欠拟合虽然也有不错的参考价值——该指标高时,对应的选择情景中一定出现了模型难以解释的选择结果。然而这种异常是不是真的由选择背后的偏好系数不同所造成的呢,答案并不乐观。我们可以构建在1000个正常样本,它们采用相同的偏好系数进行选择,然后再设计了5个特殊样本,各自采用不同的偏好系数进行选择。理论上说,这5个特殊样本应当会出现欠拟合,对应的欠拟合指标应当较高,然而实际中的表现却不稳定,有时会出现这样的结果:欠拟合指标最高的5个样本中,包括一定的正常样本;而我们设计的5个特殊样本中,有几个的欠拟合指标并不那么高。
这就有点尴尬了,但确实如此。经过分析,有两方面原因:
1)正常样本为什么欠拟合:主要是随机误差所致。特别是两个选项A/B的理论选择概率接近时,比如0.6 vs. 0.4,那么随机误差有相当大的概率(40%)导致在一次选择中选择了小概率的选项B,此时,该次选择的欠拟合指标就会偏高;
2)异常样本为什么没有欠拟合:这是因为不同的两组偏好系数,甚至是符号相反的两组偏好系数,在特定的某一个选择情景上得到相似的选择结果!
第2)点是相当令人失望的,这等于有很多组系数都可以看似合理地解释某个观察到的选择结果,这些系数自己甚至可以自相矛盾。例如,我们使用2个自变量x1和x2去分析有两个选项A/B的选择,A选项的自变量取值为x1(A)=2, x2(A)=2;B选项的自变量取值为x1(B)=1, x2(B)=1;如果x1的系数beta1=-2, x2的系数beta2=5,那么此时A的效用为2*(-2)+2*5=6,B的效用为1*(-2)+1*5=3,A>B,选A的概率更高;如果换一组系数,beta1=1, beta2=1,那么此时A的效用为2*1+2*1=4,B的效用为1*1+1*1=2,A>B,还是选A的概率更高。但是注意到,这两组系数在beta1上的符号是相反的,一个是负相关,一个是正相关,当我们观察到实际选A时,又怎么能知道x1在这里到底应该是正效用,还是负效用呢?当然啦,这实际上又涉及样本量不足、自由度过大的问题,当有很多次选择样本时,整体意义上的平均偏好是没有问题的,但是对于一次特定的选择而言,即使它是真的异常样本,光从表现上看也是有可能发现不了的。
综上所述,我认为这些指标最大的意义是通过“系数影响指标”快速检查我们的模型有没有被扭曲的风险,该指标对应于线性回归中的库克距离(cook distance),那么我们暂且采用相同的标准,如果指标>0.5时就要关注这个样本。第2个意义是通过欠拟合指标评价既有模型在每次选择中的拟合优劣,但拟合的好不代表这个样本的偏好就一定是模型估计出来的偏好,拟合的不好也不代表这个样本的偏好就一定不同,只作为参考。第3个意义是如果想通过每个样本在模型上的表现进行聚类的话,应当采用欠拟合指标而非系数影响指标,当然了,既然每一个独立个体的偏好那么难以把握,这种方法是否合理也应该进一步探讨。
最后附上两段python代码。change_beta.py是比较系数的理论变化和实际变化的,logit_leverage.py是检查3个特殊样本的残差指标的。两个文件中都包含这些残差指标的计算过程,可供参考。
