写在前面 Notice
1. 这是一个完全免费的工具。
This is a completely free tool.
2. 我不是专业码农,因此不能保证功能不出现问题。如果你在使用中发现任何bug,请和我联系,除了用户电脑本身的问题以外,绝大多数的问题都可以得到及时解决。
It is hard to get rid of all bugs, and I cannot make guarantee for the functionality of the tool. If you find any bug when using it, please contact with me. I promise that most of the problems (expect those caused only by your computer) could be solved in time.
3. 本工具基于Python 3.6开发,是国庆假期在家练习Tkinter时写的。与之前基于Matlab写的工具相比,基于Python的好处是不用再安装运行环境了,直接下载、解压后找到exe文件就可以用,坏处是打包后的文件有点大。
This tool is developed based on Python 3.6. Compared with Matlab-based tools, python-based tools do not need additional installation of Runtime and thus could be directly executed by double-clicking .exe file, however, they seems to be much larger in file size.
下载 Download
方式一:从以下链接下载打包好的exe文件,相对较大,下载并解压缩后,直接运行文件夹中的exe文件即可,无需安装python。提取码:1234
Option 1. Download the executable (packed in zip file) and directly use it without needs to install python.
QQ聊天记录分析工具-exe版 (QQ Chat History Analyzer, executable)
方式二:如果有python基础,并安装了python3,那么可以下载下面的zip文件,里面包含了一个py文件和一个停用词字典,把二者放在同一目录下,运行py文件即可。需要注意的是,运行本文件需要一系列的python依赖包,包括:re, pandas, numpy, tkinter, sklearn, matplotlib, networkx, jieba, wordcloud, zhon.
Option 2. Those who have already installed python3 could use following zip file, which contains a py file and a stop words dictionary. Please note that this py file would have to import several modules, including re, pandas, numpy, tkinter, sklearn, matplotlib, networkx, jieba, wordcloud, zhon.
QQ聊天记录分析工具-python源码 (QQ Chat History Analyzer, python code)
视频示例 Demo Video
功能介绍 Introduction of functionality
QQ是大概是最常用的即时聊天工具了。日积月累的QQ聊天记录就像日记一样留存了各种历史信息,从中可以获得一些有意思的发现。用户可以通过本工具分析QQ群记录或两人之间私聊记录,包括记录量随着时间的变化,群成员的基本特征(发言次数,活跃时间,话题的开始者/结束者,回复的滞后时间等),文本分析(词云、聊天摘要),联系分析(“我”与其他人的关系,社会网络图)等。
QQ is the most popular live chat tool in China. QQ chat history records so many information, from which some interesting findings could be derived. This tool allows users to analyze QQ group chat or private chat history, including time series analysis, basic features of group members (chatting frequency, active period, frequency of starting/ending a topic,…), textual analysis (word cloud, chatting summary), association analysis (‘I’ vs. others, social network graph), etc.
用户首先从QQ中导出一个txt格式的聊天记录文件,将其导入本工具中,然后经过预处理(利用正则表达式提取每一条消息的相关信息)、设定昵称这两步之后,即可以开展上面的各项分析。某项功能暂时不可用、需要先运行其他功能时,相应的按钮是灰色的,因此,用户可以很清楚地了解分析的前后步骤。
Users could export a chat history record file in txt format from QQ and then import it to this tool. Two necessary steps are pretreatment of the txt file (using regular expression to extracting messages one by one) and specification of nicknames. After that, users could run kinds of analysis according to the instructions that whether a button is grey (unavailable now and need something run before) or black (available now).
以下是一些分析案例,出于隐私的考虑,群成员的昵称都被设置成了A/B/C/D….
Followings are some examples of results. Considering privacy, all nicknames are set to A/B/C/D….
首先是时间统计,包括按年/月/日的时间线统计,也包括按一日24小时的统计。
Let’s start with statistics concerning time, including statistics by year/month/day as well as by 24 hours in a day.
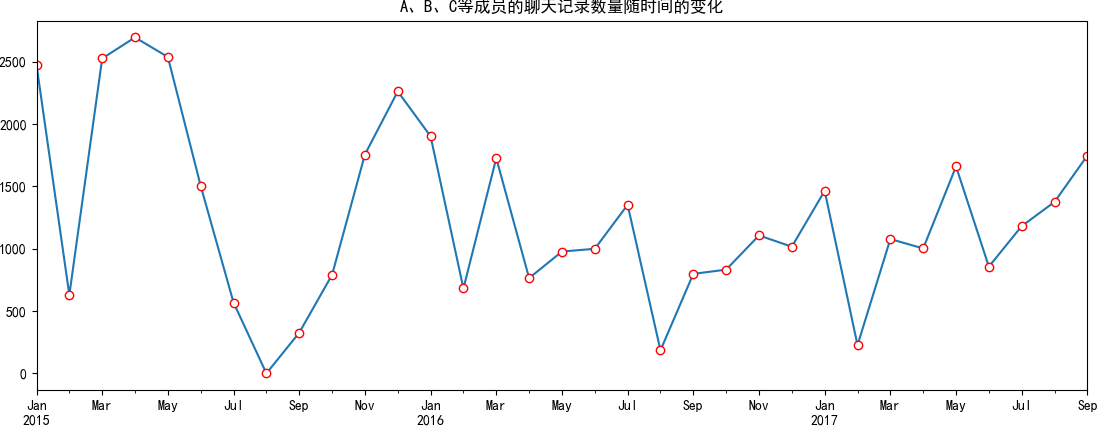
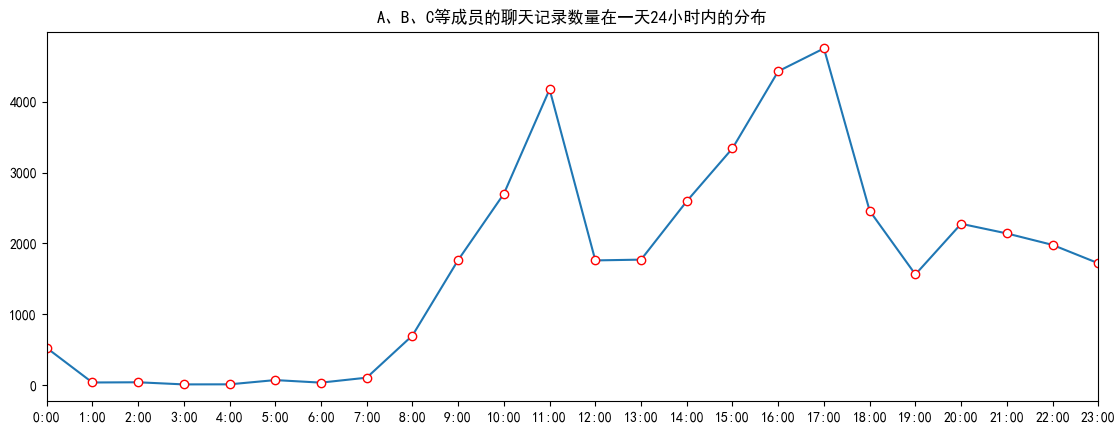
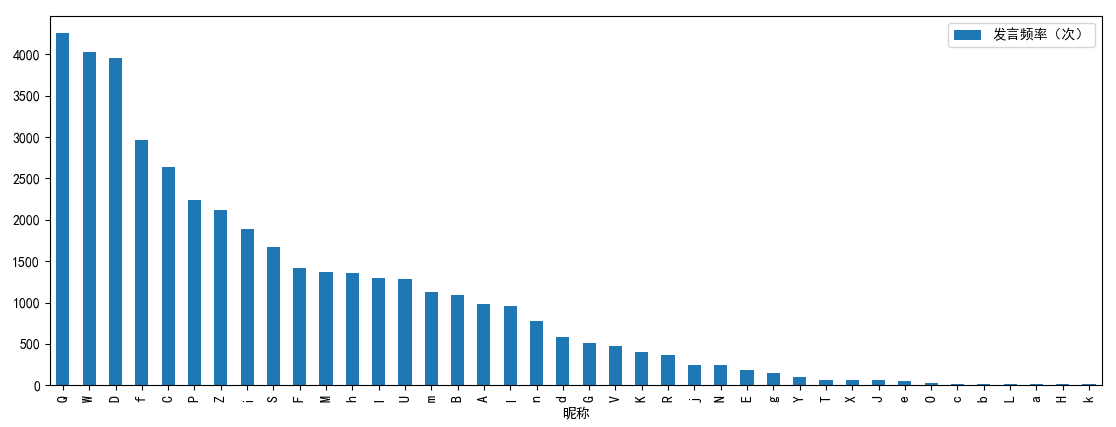
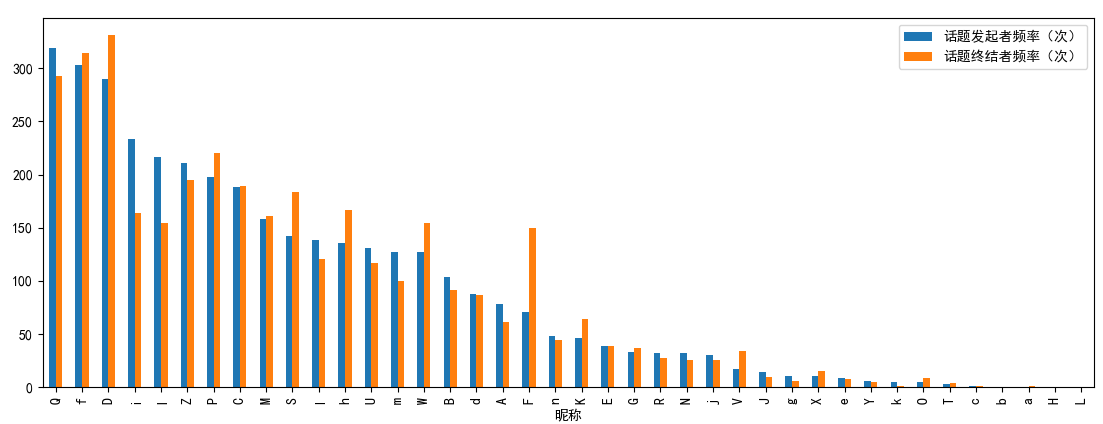
现在是每位成员的基本特征,例如发言频率,成为话题发起者/终结者的次数等。
Now let’s move to basic chatting features of each member, such as chatting frequency, as well as frequencies of starting/ending a topic.
下面是有关成员之间联系的分析,比如:谁回复我最多,我回复谁最多?
Followings are about associations among members. For example, who replies to me most, and to whom I reply most?

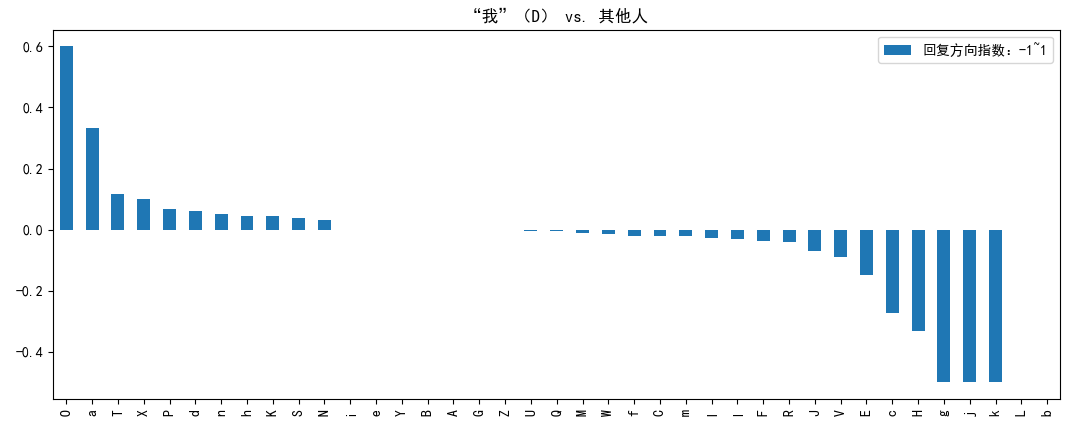
下图中,回复的方向指数=(谁回复我-我回复谁)/(谁回复我+我回复谁)。因此,当该指数为0时,表示我和那个人有来有往;当指数为1时,表示那个人不停地回复我,而我从来不回复Ta;当指数为-1时,表示我一直在回复Ta,可Ta却从不理我。对于图中的D同学,O同学常单方面地跟Ta聊却得不到足够回应;相反地,D同学常单方面地跟g,j,k同学聊却得不到足够回应。
The direction index (DI) in the following figure is calculated as (x-y)/(x+y), where x represents the amounts of others replying to me and y represents the amounts of I replying to others. DI=0 means the two person are chatting with each other in a balanced way; DI=1 means someone is keeping reply to me while I never reply to him/her; vice verse for DI=-1.
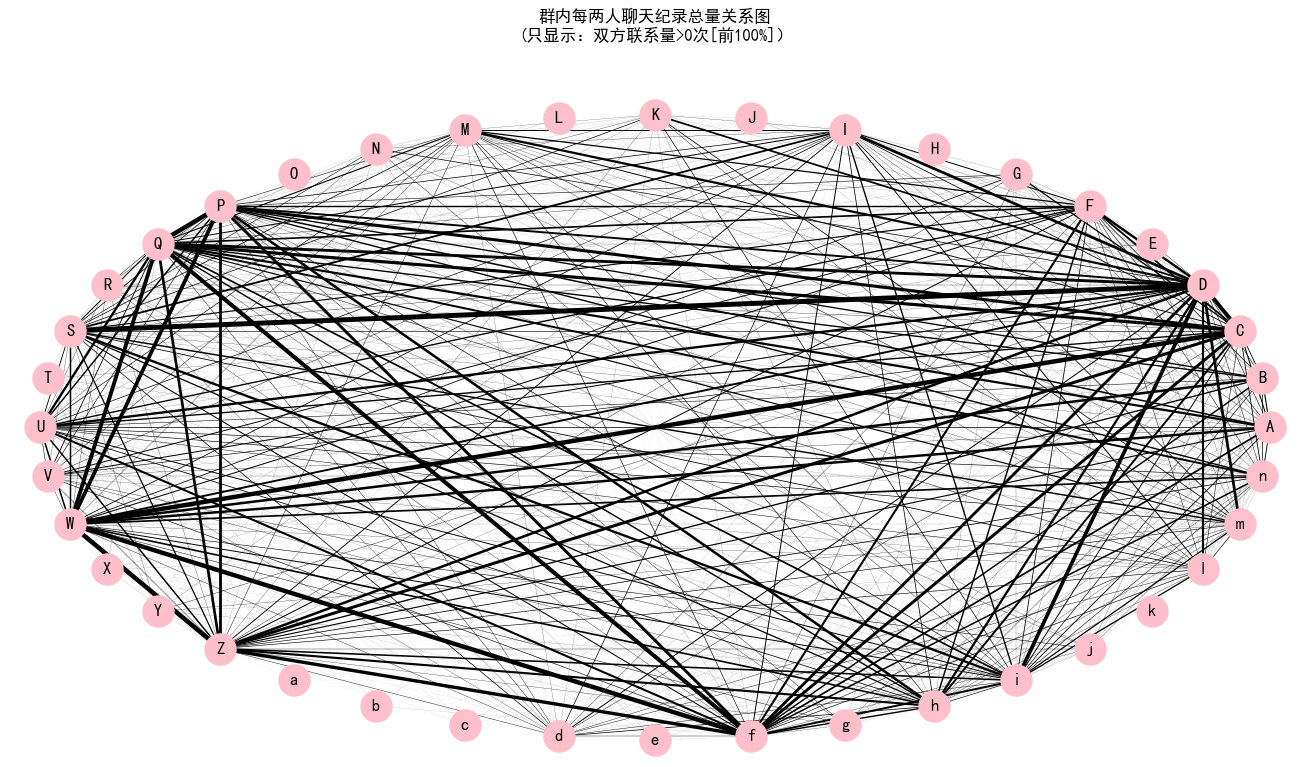
下面的网络图通过线的粗线反映了每两位成员的联系总量的大小。
The network graph below shows the total amount of replies between each pair of members by the thickness of the line.
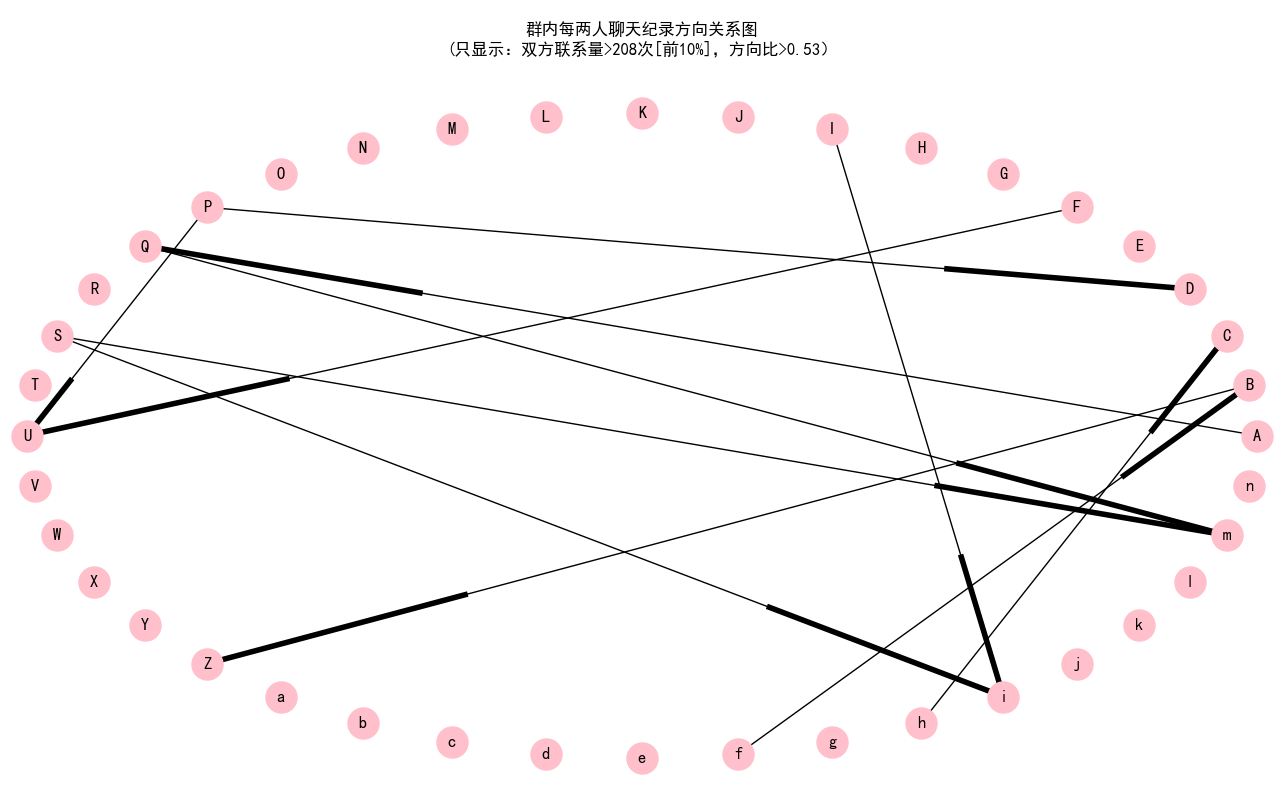
除了总量以外,也可以通过网络图反映每两个成员之间回复关系的方向性。对于A与B,如果A回复B的数量占A与B相互回复总数的50%以上,就会用A→B的箭头反映这种不平衡性。在下图中,只有这种方向比在53%以上才会显示出来。
In addition to total amount, the network graph could also illustrate the directions. For A and B, if the amount of A replying to B is more than half of the total amount (A replying to B plus B replying to A), this kind of unbalance would be represented by an arrow A→B. In the following graph, a more strict threshold (53%) is used.
最后来看文本分析,首先是生成词云。有三种生成词云的方法:默认是TF-IDF,即:一个词在本文中出现的频率越高,以及它在其他文件中出现的频率越低,则它作为关键词的权重越大;第二方法更简单,只考虑词在本文中出现的频率,但这样容易混入许多“放之四海而皆准”的没有特色的普通词;第三种方法是TextRank算法,是基于词与词之间在5步内的共现关系构建词网,然后利用社会网络分析的方法计算Rank指标。通常来看,采用默认的TF-IDF法即可。生成词云的基础是分词,用户可以对数字、英文、停用词字典、自定义字典等进行设置。
Finally, let’s move to textual analysis. This tool could generate word cloud by 3 algorithms. The default one is TF-IDF, i.e., term frequency – inverse document frequency. The second one only considers term frequency. The third one is TextRank, which is based on the text network. Parsing is the foundation of word cloud. For parsing, this tool allows specifications of numbers, letters, stop words dictionary, user-defined dictionary, and so on.
下图显示了某群中所有人聊天记录的词云。于是这个群是关于什么的,应该很清楚了……
The following picture illustrates the word cloud for the records of all members.

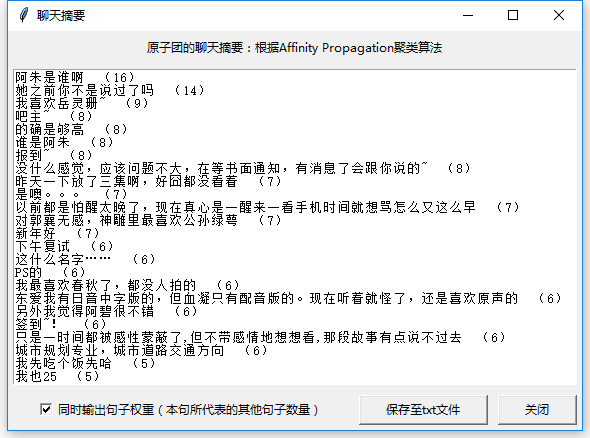
更复杂的文本分析是以句子为单位,提取关键句,形成摘要。这一部分功能还只是尝试。主要算法是计算每两句话之间的相似度,然后利用相似性传播聚类(Affinity Propagation Cluster)算法提取能够代表其他句子的原型句,或者是通过TextRank算法提取在句子相似性网络中中心度较高的句子。
More complex textual analysis is to extract key sentences to generate a chatting summary. This function is only a first attempt. The algorithms are as follows: firstly, measure the similarities between each pair of two sentences, then apply affinity propagation cluster algorithm to extract exemplars which could represent other sentences, or use TextRank algorithm to extract key sentences with high degree in the sentence network.
下面这张图是我本人在这个群里的发言的聊天摘要……这种分析太容易暴露隐私了。
Here is my personal chatting summary.

在“设定分析中使用的昵称”时软件会自动关闭,请问如何解决?分析的群有两千人,记录约一万三千条。如能邮件答复更好,谢谢!
有人有这个文件的链接可以发给我嘛
您好,链接失效了,请问可以重新发送嘛?非常感谢
您好!第一個下載連結失效了,請問能請您重新發一個嗎?
十分感謝!
Hi, the link was expired, but it should be very useful! May you upload it again, that will be so great!
暗室逢灯啊